
Recently, I received a product announcement email from a large ISV about a new free tool that is designed to scan a database schema for columns with names that are frequently associated with sensitive data such as social security numbers, dates of birth, credit card numbers, etc. It caught my attention because I had previously used a T-SQL script to scan column names, and was curious what added value their tool provided. Apart from a GUI and some pre-built column name definitions, I found it did basically the same thing; find columns with names that include known values such as “ssn”, “birthdate”, etc.
While this could certainly help you identify data that may need to be encrypted, scrubbed for development, or simply documented, it seems to me that it could create a false sense of security if one were to employ the tool as a primary means of identifying sensitive data. I am aware that companies release free tools like this to give potential customers a taste of some of what is available in their more full-featured products, but the way it was presented seemed to completely ignore its shortcomings and the associated potential liability.
The problem with this type of tool is that it’s only providing a small part of the solution. It’s not looking at the data itself, only the column names. Since column names can be named just about anything, you’re taking a pretty big gamble by expecting them to match nicely named patterns such as “%birth%,%dob%” or “%social%,%ssn%”.
Let’s look at an example…
I created a new table and loaded it up with a couple of sample rows as follows:
CREATE TABLE [AllPersonalData] ( [RowID] INT NOT NULL IDENTITY(1, 1) ,[FirstName] NVARCHAR(20) ,[LastName] NVARCHAR(20) ,[SSN] CHAR(11) ,[CCNum] BIGINT ,[DOB] DATE ,CONSTRAINT [PK_AllPersonalData_RowID] PRIMARY KEY CLUSTERED ([RowID] ASC) ); INSERT INTO [dbo].[AllPersonalData] ([FirstName] ,[LastName] ,[SSN] ,[CCNum] ,[DOB] ) VALUES (N'John' ,N'Doe' ,'222-44-8888' ,4444888833337777 ,'01/31/1973' ); INSERT INTO [dbo].[AllPersonalData] ([FirstName] ,[LastName] ,[SSN] ,[CCNum] ,[DOB] ) VALUES (N'Jane' ,N'Doe' ,'555-22-7777' ,4321789031234321 ,'04/12/1984' ); SELECT * FROM [dbo].[AllPersonalData];
The table now looks like this:
RowID FirstName LastName SSN CCNum DOB ----------- -------------------- -------------------- ----------- -------------------- ---------- 1 John Doe 222-44-8888 4444888833337777 1973-01-31 2 Jane Doe 555-22-7777 4321789031234321 1984-04-12
If I run the tool against this table, I get the following results:
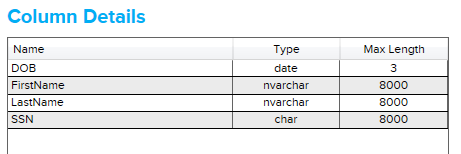
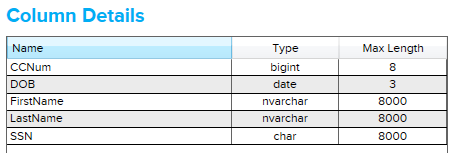
Notice that the CCNum column wasn’t identified, even though it contained a very credit card-like 16-digit integer. If I edit the search string for credit card numbers to be “%credit%,%card%,%cc%“, now it finds it:
Now let’s create a couple of new columns and copy sensitive data into them:
ALTER TABLE [dbo].[AllPersonalData] ADD [NationalIdent] CHAR (11);
ALTER TABLE [dbo].[AllPersonalData] ADD [PmtNum] BIGINT ;
UPDATE
[dbo] .[AllPersonalData]
SET
[NationalIdent] = [SSN]
,[PmtNum] = [CCNum];
Now for both the SSN and the CC number, we have two columns each:
RowID FirstName LastName SSN CCNum DOB NationalIdent PmtNum ----------- -------------------- -------------------- ----------- -------------------- ---------- ------------- -------------------- 1 John Doe 222-44-8888 4444888833337777 1973-01-31 222-44-8888 4444888833337777 2 Jane Doe 555-22-7777 4321789031234321 1984-04-12 555-22-7777 4321789031234321
Let’s see what the tool finds now…
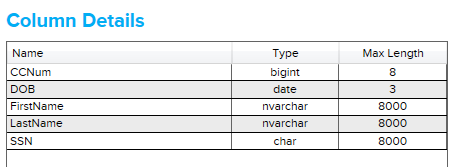
No change.
I’ve worked with enough third-party databases to know that columns aren’t always named in an intuitive manner, or even consistently across different tables. This is especially true when the ISV is based in another country where the local terminology might be different than what you’re used to. Some applications allow users to add user-defined fields, which can end up in generic named columns (such as UserDefField1, UserDefField2 etc.), or even in XML… Which brings me to a real world scenario I encountered recently.
I was tasked with restoring a copy of an HR database to a development server. Access to the dev server was fairly restricted, but the data still needed to be scrubbed for obvious reasons. The person previously responsible for this task had left the company, but they had shared the script they used to strip all sensitive data from the database. Or so they thought…
The first thing I did after reviewing the script was to run a simple query to identify any columns in other tables with the same names as those being scrubbed (similar to what this tool is doing behind its GUI):
SELECT
'[' + OBJECT_NAME( [o].[object_id] ) + ']' AS [Object]
,'[' + [c] .[name] + ']' AS [Column]
FROM
[sys] .[columns] [c]
JOIN [sys]. [objects] [o] ON [c] .[object_id] = [o].[object_id]
WHERE
[o] .[type] IN ('U' )
AND ( [c].[name] LIKE '%mail%'
OR [c]. [name] LIKE '%first%name%'
OR [c]. [name] LIKE '%last%name%'
OR [c]. [name] LIKE '%birth%'
OR [c]. [name] LIKE '%address%'
OR [c]. [name] LIKE '%phone%'
OR [c]. [name] LIKE '%social%'
OR [c]. [name] LIKE '%ssn%'
OR [c]. [name] LIKE '%gender%'
OR [c]. [name] LIKE '%age%'
);
This turned up a few other instances that were previously being missed. While investigating those instances, I noticed a few other column names that caught my attention such as [profitsharing], [datewhen60], and [transitabanumber]. Those are the types of column names that are easily identified as containing potentially sensitive information, but unique enough that they’re not something you immediately think of when you’re compiling a list of column names to search. This made it apparent that I would need to do a more comprehensive search of the database for sensitive data itself, not just column names.
I downloaded a tool called OpenDLP in the form of a VirtualBox virtual appliance. OpenDLP is an open source, agentless scanning tool that uses regular expressions to search data in file shares as well as databases, and includes a connector for SQL Server. After experimenting with the settings a bit and getting a feel for the tool, I pointed it at a copy of the HR database and let it fly…
OpenDLP found a lot of the same data that I already knew about and that I would have been disappointed had it not found, but there was one nugget that no amount of column name scanning would have ever discovered – XML data within an NVARCHAR(MAX) column in an obscurely named table. This column was flagged for containing social security numbers, but deeper analysis found it also contained birth dates, drivers license numbers, as well as next-of-kin information for job applicants.
My initial thought for dealing with this data was to pull the XML out into a temp table with an XML data type so that I could perform XQuery updates against the sensitive elements, then push the modified XML back to the original table (cast back to NVARCHAR) as an UPDATE. However, I found that the schema varied by row. That was going to be way more XQuery than I wanted to write, and the data wasn’t needed for development efforts, so the simple decision was to just NULL out the column entirely.
The lesson learned is that data scrubbing can be a complex, multi-faceted endeavor, particularly when dealing with a database schema developed by a third-party.
